
Distributed System
In this article we will learn about basic concepts of distributed system


Table of contents
- What is a Distributed System?
- Why there is a need for a distributed system?
- The architecture of the distributed system
- Process Synchronization in distributed systems
- Clock Synchronization
Distributed systems are used in various applications ranging from e-commerce websites to large-scale data processing applications.
A distributed system is a collection of independent computers that communicate and coordinate with each other to achieve a common goal.
In this blog, we will discuss what a distributed system is, why there is a need for a distributed system, and the concepts of a distributed system.
What is a Distributed System?
As per Wikipedia:-
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another.
Easiest Definition:-
A distributed system in its simplest definition is a group of computers working together to appear as a single computer to the end user.
The computers in a distributed system are connected by a communication network, such as the Internet. Each computer in a distributed system performs a specific task, and the results of the tasks are combined to achieve a common goal.
Why there is a need for a distributed system?
A distributed system is designed to provide high availability, scalability, and fault tolerance.
1.High Availability
In a distributed system, if one computer or server fails, the other computers or servers can continue to function.
This means that the system remains available to the users even if some of the nodes or servers are down.
A distributed system can provide higher availability than a centralized system.
2.Scalability
A distributed system can scale horizontally, which means that more computers or servers can be added to the system to handle the increased workload.
This means that a distributed system can handle a larger number of users or requests without any performance degradation.
A centralized system may not be able to scale to handle a large number of users or requests.
3.Fault Tolerance
In a distributed system, if one node or server fails, the system can still function.
The workload can be distributed among the remaining nodes or servers.
This means that a distributed system is more fault-tolerant than a centralized system.
4.Geographic Distribution
A distributed system can be geographically distributed, which means that the nodes or servers can be located in different locations.
This can help to reduce the network latency and improve the performance of the system.
It also means that the system can continue to function even if there is a natural disaster or other disruption in one location.
5.Load Balancing
In a distributed system, the workload can be distributed among the nodes or servers.
This can help to balance the load and ensure that no node or server is overloaded.
Load balancing can help to improve the performance and reliability of the system.
6.Cost-effectiveness
A distributed system can be more cost-effective than a centralized system.
Instead of purchasing a large, expensive server, multiple low-cost computers or servers can be used.
This can help to reduce the overall cost of the system.
The architecture of the distributed system
The architecture of a distributed system refers to the structure of the system, including its components and how they interact with each other.
Client-Server: In this architecture, clients request services from servers, which provide the services. The server is responsible for managing the resources required to provide the service.
Peer-to-Peer: In this architecture, all nodes in the system have equal capabilities and responsibilities. Nodes can request services from other nodes and can also provide services to other nodes.
Hybrid: In this architecture, multiple architectures are combined to provide a more robust and scalable system. For example, a client-server architecture can be combined with a peer-to-peer architecture to provide better fault tolerance and scalability.
Process Synchronization in distributed systems
Process synchronization is the process of coordinating the actions of multiple processes to ensure that they do not interfere with each other.
When we have multiple processes running simultaneously in a computer or a distributed system, they might need to access the same resources like memory, files, or devices. If two or more processes try to access the same resource at the same time, it can lead to conflicts, race conditions, or incorrect results.
Process synchronization is a way to coordinate the actions of these processes so that they work together without interfering with each other. It involves using different techniques or mechanisms to manage access to shared resources and ensure that each process gets the resource it needs at the right time.
Example
Imagine two people collaborating on a Google document online on different computers. They are both working on the same section of the document, and they both try to edit it simultaneously. This can lead to conflicts and overwrite each other's changes, causing data inconsistency.
To prevent this, process synchronization techniques like locks or semaphores can be used to ensure that only one person can edit that section of the document at a time.
Clock Synchronization
Synchronization is important in distributed systems because it ensures that multiple processes or components of the system are coordinated and working together properly. In a distributed system, multiple machines or processes may be working on different parts of a task, and it is essential to synchronize their actions to avoid conflicts or inconsistencies.
Clock synchronization is a particularly important aspect of synchronization in distributed systems because it enables different components of the system to agree on the order of events. In a distributed system, different machines or processes may have their local clocks, but these clocks may not be perfectly synchronized. This can lead to inconsistencies in the order of events, which can cause errors and make it difficult to reason about the behavior of the system as a whole.
By synchronizing the clocks across the different components of the system, it becomes possible to establish a global ordering of events that all components can agree on. This can be achieved through a variety of techniques, such as using a centralized time server or using algorithms that allow components to adjust their clocks based on messages exchanged with other components.
There are two types of clocks in the distributed system:-
Physical Clock
Logical Clock
Physical Clock
Physical clocks are based on the oscillation of a piezoelectric crystal or a similar integrated circuit. Each system in a distributed system has its physical clock that keeps time.
These clocks are relatively precise, reliable, and accurate, but they are not flawless. They will differ from the correct time, and the clocks on each system will drift away from the true time at a different rate and in a different direction. This means that coordinating physical clocks across several systems is possible but will never be completely accurate.
Types of clock synchronization algorithms in physical clock
Cristian Algorithm
Berkeley Algorithm
Network Time Protocol
Logical Clock
Logical clocks are a technique for recording temporal and causative links in a distributed system. They create a protocol on all computers in a distributed system so that the computers can keep a uniform ordering of happenings inside some virtual time range.
Logical clocks provide for the global ordering of occurrences from various processes in certain systems, especially in cases where physically synchronized global clocks are not available. Logical clocks use algorithms to assign timestamps to events that occur in the system, even when there is no physical relationship between the clocks on different systems.
Types of clock synchronization algorithms in logical clock
Lamport timestamps: Lamport timestamps assign a unique timestamp to each event in a distributed system. The timestamps are based on the process that generated the event and the time when the event occurred. Lamport timestamps can be used to establish a partial order of events in a distributed system.
Vector clocks: Vector clocks are a more advanced logical clock algorithm that assigns a vector of timestamps to each event. Each node maintains a vector that corresponds to its own events and the events it has seen from other nodes. Vector clocks can be used to establish a total order of events in a distributed system.
Causal Ordering of messages
The causal ordering of messages is a concept in distributed systems that ensures that messages are delivered in a way that respects the causal relationships between events. In other words, if event A caused event B, then any message related to event A should be delivered before messages related to event B.
In a distributed system, messages are sent between nodes that may be physically separated by distance and connected by a network. When messages are sent, they may be delayed or delivered out of order due to network congestion, node failures, or other factors. Causal ordering ensures that even if messages are delayed or delivered out of order, the causality between events is preserved.
One approach to achieving causal ordering of messages is to use logical clocks, such as Lamport clocks or vector clocks. Each event in the system is assigned a logical timestamp, and messages carry the timestamp of the event they are related to. When a node receives a message, it checks the timestamp of the message and compares it to its own timestamp. If the timestamp of the message is later than the node's timestamp, the node can update its own timestamp and deliver the message. If the timestamp of the message is earlier than the node's timestamp, the node can buffer the message until it receives all messages with earlier timestamps.
Another approach to achieving causal ordering is to use causal message ordering protocols, such as Total Order Broadcast (TOB) or Atomic Broadcast (AB). These protocols ensure that messages are delivered in the same order to all nodes in the system, based on the causal relationships between events. This ensures that all nodes see the same sequence of events and that causality is preserved.
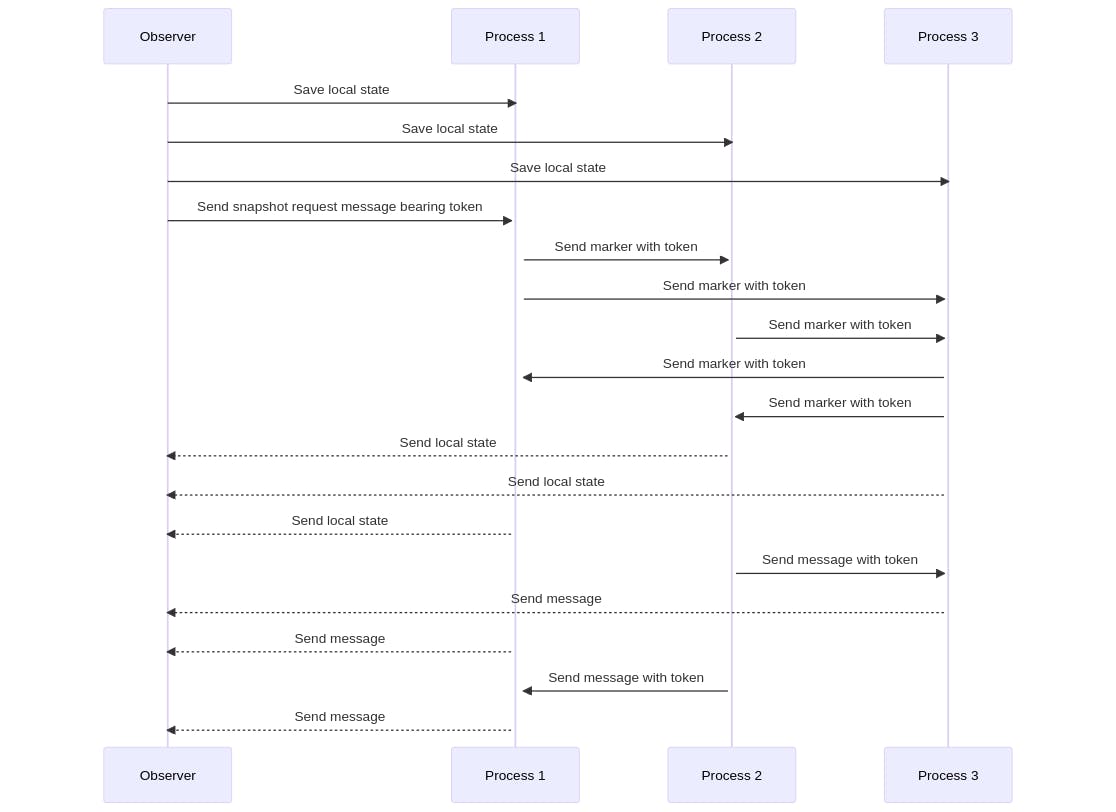
Chandy–Lamport’s global state recording algorithm
The Chandy-Lamport global state recording algorithm is a method for recording a consistent snapshot of a distributed system's state. The algorithm allows us to capture a snapshot of a distributed system at a specific point in time, even though events may be happening concurrently across different processes in the system.
Assumptions:
There are no failures and all messages arrive intact and only once
The communication channels are unidirectional and FIFO ordered
There is a communication path between any two processes in the system
Any process may initiate the snapshot algorithm
The snapshot algorithm does not interfere with the normal execution of the processes
Each process in the system records its local state and the state of its incoming channels
The algorithm works using marker messages
Algorithm:
The observer process (the process taking a snapshot) saves its own local state.
The observer process sends a snapshot request message bearing a snapshot token to all other processes.
A process receiving the snapshot token for the first time on any message sends the observer process its own saved state.
The process attaches the snapshot token to all subsequent messages to help propagate the snapshot token.
When a process that has already received the snapshot token receives a message that does not bear the snapshot token, this process will forward that message to the observer process. This message was obviously sent before the snapshot “cut off” and needs to be included in the snapshot.
From this, the observer builds up a complete snapshot: a saved state for each process and all messages “in the ether” are saved.
The algorithm works by using marker messages to propagate the snapshot request to all processes in the system.
When a process receives the snapshot token for the first time, it saves its local state and sends it to the observer process. It then attaches the snapshot token to all subsequent messages it sends to help propagate the snapshot request to other processes.
When a process receives a message that does not bear the snapshot token, it forwards that message to the observer process, as it must have been sent before the snapshot cut off and needs to be included in the snapshot.
Cuts in the distributed system
A cut is a way to divide the system into two parts, and the events in the system can be categorized as past or future.
Consistent Cut:- If in a cut a message sent from the past or left side is always received in past then it is known as a consistent cut.
Inconsistent Cut:- If in a cut a message sent from the past is received in the future or vice-versa then it is known as an inconsistent cut.
Termination Detection in Distributed Systems
The concept of a process state forms the basis of termination detection in distributed systems.
A process can be in one of two states: active or idle.
An active process can become idle at any time, but an idle process can only become active upon receiving a computational message.
Termination is said to have occurred when all processes in the distributed system become idle, and there are no computational messages in transit.
Huang's Algorithm for Termination Detection
Initially, all processes in the system are idle.
A distributed task is initiated by a process sending a computational message to another process. This process is referred to as the "controlling agent".
The initial weight of the controlling agent is typically set to 1.
The following rules are applied during the computation:
A process that sends a message splits its current weight between itself and the message.
A process that receives a message adds the weight of the message to itself.
Upon becoming idle, a process sends a message containing its entire weight back to the controlling agent and goes idle.
Termination is said to have occurred when the controlling agent has a weight of 1 and is in an idle state.
Distributed Mutual Exclusion
Distributed mutual exclusion is a mechanism used in distributed systems to ensure that concurrent processes do not access shared resources at the same time, which could lead to data inconsistencies and conflicts. In a distributed system, processes communicate and coordinate with each other to ensure mutual exclusion.
Classification of Distributed Mutual Exclusion:
Token-based algorithms: In these algorithms, a token is passed between the processes, and only the process holding the token can access the shared resource.
Non-token-based algorithms: In these algorithms, a process requests access to the shared resource and is granted permission based on some criteria such as priority, timestamp, or queue.
Quorum-Based Approach: Instead of requesting permission from all other sites, each site requests a subset of sites, known as a quorum. Any two subsets contain a common site responsible for ensuring mutual exclusion.
Requirements of Mutual Exclusion Algorithm:
No Deadlock: No site should wait indefinitely for a message that will never arrive.
No Starvation: Every site that wants to execute the critical section should get an opportunity to execute it in finite time.
Fairness: Each site should get a fair chance to execute the critical section, and requests for critical section execution should be executed in the order they arrive in the system.
Fault Tolerance: The algorithm should be able to recognize failures and continue functioning without disruption.
Performance Metrics for Mutual Exclusion Algorithms:
Message Complexity: The number of messages required to enter and exit the critical section.
Time Complexity: The amount of time required to enter and exit the critical section.
Scalability: The ability of the algorithm to handle an increasing number of processes and requests for critical section execution.
Overhead: The additional resources required to implement the algorithm, such as memory and CPU usage.
That's all!
Thanks for reading
Please upvote if you liked the article.